STD
-
Paper: STD: Stable Triangle Descriptor for 3D place recognition [ICRA23]
-
Reference: Github link, Youtube link, arXiv link

Problem Definition
- LiDAR 기반의 place recognition은 viewpoint에 관계없이 rigid transformation에 invariant해야한다.
- 이후 point cloud registration 과정을 위해 좋은 initial guess를 주어야 한다.
- ICP와 같은 local registration 알고리즘은 initial guess에 따라 성능(정확도, 속도)이 크게 좌우되기 때문이다.
- LiDAR의 sparsity problem에 robust해야 한다.
Contributions
- 제안하는 6차원의 triangle descriptor는 rigid transformation에 invariant하며, descriptor로써의 성능 또한 좋다.
- 빠른 key point extraction 이후에 triangle descriptor를 생성한다.
- 다양한 환경과 센서를 통해 성능을 검증했다.
Pipeline
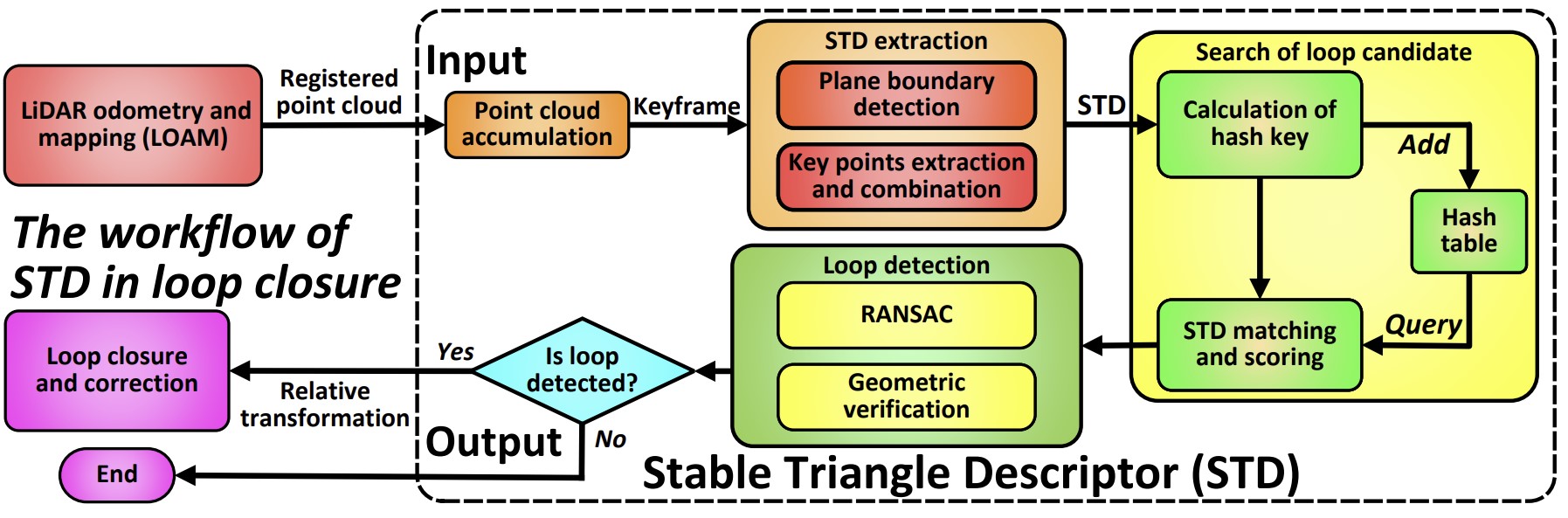
- Point cloud를 쌓아 만든 keyframe으로부터 triangle descriptor를 생성한다.
- 생성된 descriptor는 hash table에 저장된다.
- Matching score가 가장 높은 10개의 descriptor가 loop candidates로 선정된다.
- Geometric verification 과정을 통해 유효한 loop인지 판별하고, relative transformation을 구한다.
- 도출된 relative transformation은 loop closure and correction에 사용된다.
Methodology
1. Triangle descriptor generation
-
Keyframe 생성 - Plane voxel & Boundary voxel 생성 - Image로부터 key point 선정 - Descriptor 생성
-
Points accumulation을 하여 일정 크기의 submap을 만들어 하나의 keyframe으로 선정한다. 이를 통해 sparsity 문제나 센서, 환경에 따른 문제를 줄일 수 있다고 한다.
-
Keyframe 내의 전체 point cloud를 일정 크기의 voxel로 나누고, 한 voxle 내의 N개의 points에 대해 covariance matrix를 구한다. Covariance matrix로 부터 second eigen value, third eigen value를 구하고, hyperparameter와 비교하여 해당 voxel이 평면을 구성하는지 체크한다. 같은 평면의 voxel들은 모두 plane voxel 이라고 한다.
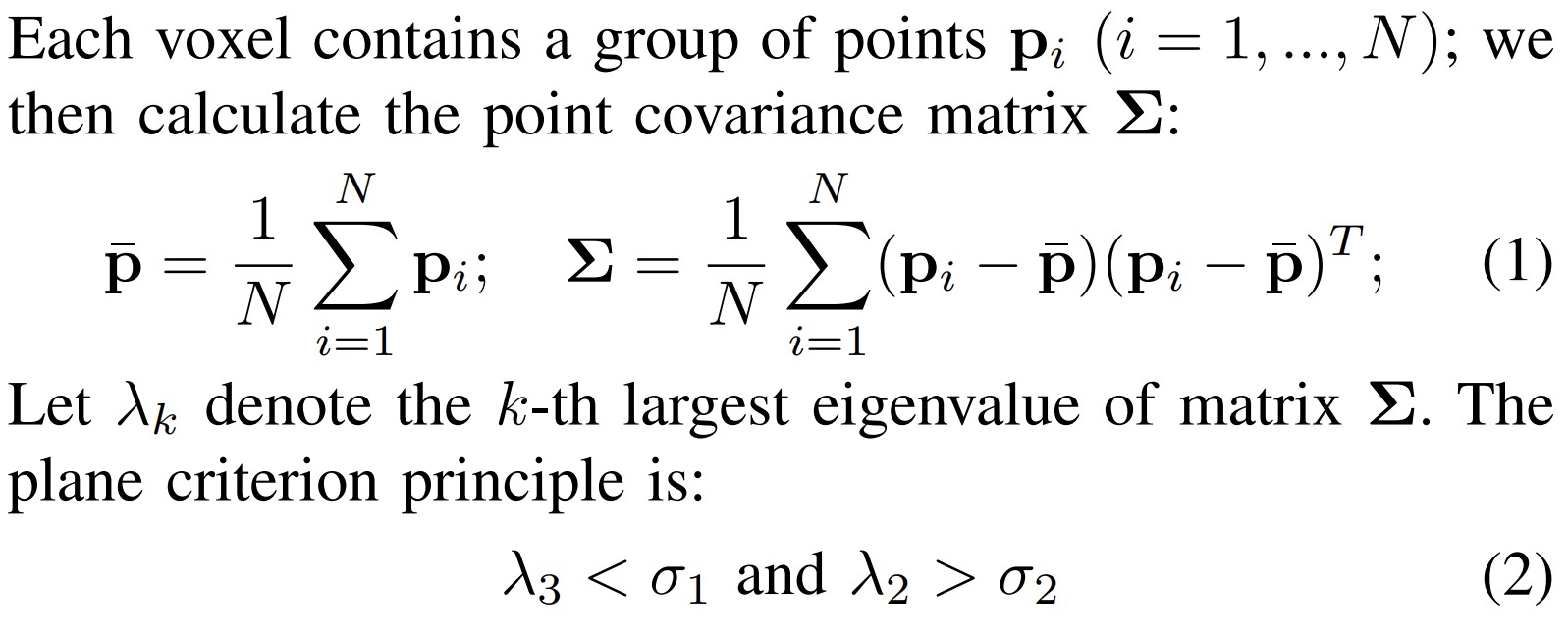
-
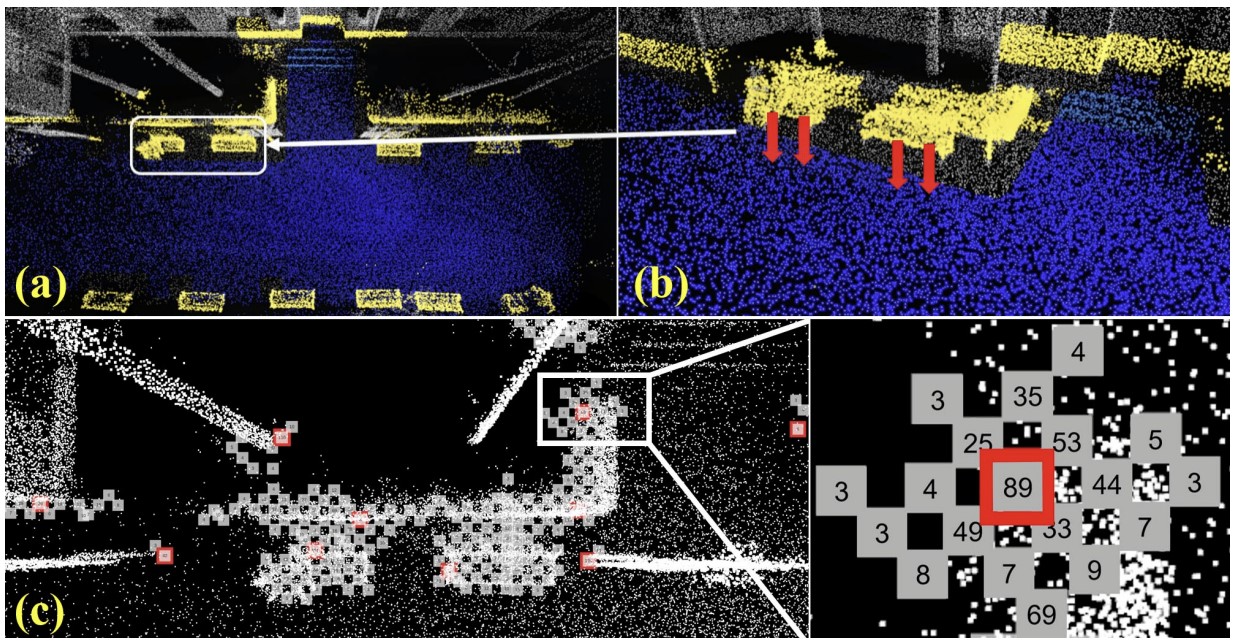
주변 voxel로 확장해나가면서 plane normal의 방향을 비교하며 같은 평면을 구성하지 않는 voxel에 대해서는 boundary voxel 리스트에 추가한다. Boundary voxel 내의 points를 평면으로 image projection을 시키고, 한 픽셀의 대표값은 평면으로부터 가장 먼 거리로 선정한다. (가장 높은 위치에 있는 point와 평면까지의 거리가 될 것이다.) 이후, 5*5 neighborhood 내에서 가장 큰 pixel value를 가지는 픽셀을 key point로 선정한다.
-
하나의 keyframe에서 추출된 key points들로부터 triangle descriptor 생성을 위해 k-D tree로 20개의 near neighbor points를 찾는다. (같은 길이의 빗변을 가지는 삼각형은 중복으로 간주해 제거) 각 triangle descriptor는 3개의 변과 3개의 projection normal vector로 총 6차원으로 구성된다.

- Projection normal vector는 key point가 추출된 평면의 normal vector를 뜻한다.
- Descriptor와 함께 평면 또한 이후 geometrical verification 과정을 위해 모두 저장된다.
2. Search loop candidates
- Hash table 생성 - Hash key 계산 - Loop candidate score 계산
- Keyframe에서 추출된 수백개의 descriptor들은 hash table에 저장된다. Hash key는 세 변의 길이와, 세개의 normal vector 중 두개의 dot product로 구한 3가지 조합의 값으로 구성된다. (따라서 hash key는 총 6개의 value를 가짐) 이 방식을 계속 반복하며 hash table에 hash key들이 저장된다.
- 추가로, projection된 boundary points가 3D point cloud로부터 추출된 것이기 때문에 rigid transformation에 invariant하다고 한다.
- 현재 N번째 keyframe에 대한 descriptor들을 계산하고 있다고 가정하자. 현재까지 N-1개의 keyframe에 대한 수백개의 descriptor들로부터 hash key가 계산되어 hash table을 구성하고 있을 것이다. 현재 keyframe에서 하나의 descriptor를 구하고, hash key를 계산하여 hash table의 한 container에 저장이 되었다. 이 때, 해당 container에 존재하는 모든 descriptor에 대해 그 descriptor를 가졌던 keyframe들의 점수를 1점씩 올린다. 이 과정이 반복되어 현재 N번째 keyframe의 모든 descriptor들에 대한 hash key 저장이 끝났을 때, 가장 점수가 높은 10개의 이전 keyframe들을 loop candidates로 등록한다.
3. Loop detection
-
Transformation 구하기 - Plane coincidence 판별 - Valid loop detection
-
위 과정을 통해 얻어진 loop candidates들은 geometrical verification과정을 거쳐 valid한지 결정된다. 삼각형의 특성 때문에, 두 triangle descriptor가 매칭되면 쉽게 transformation을 구할 수 있다. 이를 Singular Value Decomposition(SVD)를 통해 구하고, RANSAC으로 outlier를 걸러준다.
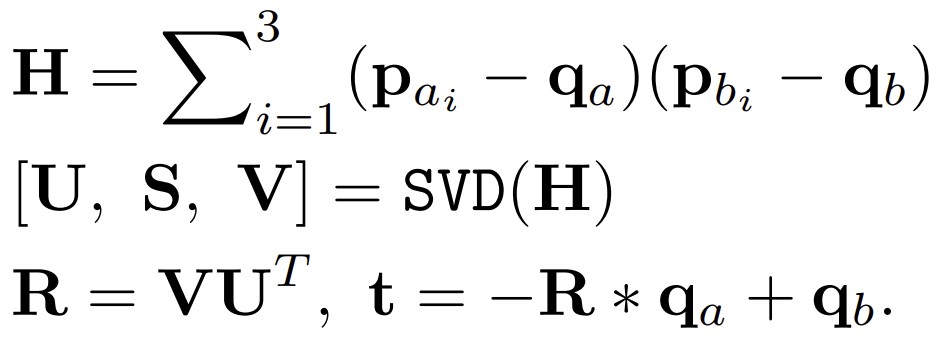
-
위에서 구한 rigid transformation으로, geometrical verification을 위해 현재 keyframe과 candidate keyframe 간의 plane overlap을 계산한다. 각 key frame에 존재하는 많은 plane voxel 마다 중심점 g 와 normal vector u가 있을 것이다. Candidate frame에 존재하는 모든 plane voxel들에 대한 중심점 g에 대해 k-D tree (k=3)를 만들고, 현재 frame의 모든 plane voxel들의 중심점 g를 candidate frame으로 변환해준다. 같은 coordinate에 존재하는 양 frame간의 중심점들에 대해 nearest point를 구해 두 평면 정보가 일치하는 지를 판단한다. 일치하는지 판단하는 기준은 normal vector의 차이와, point to plane distance를 사용한다.
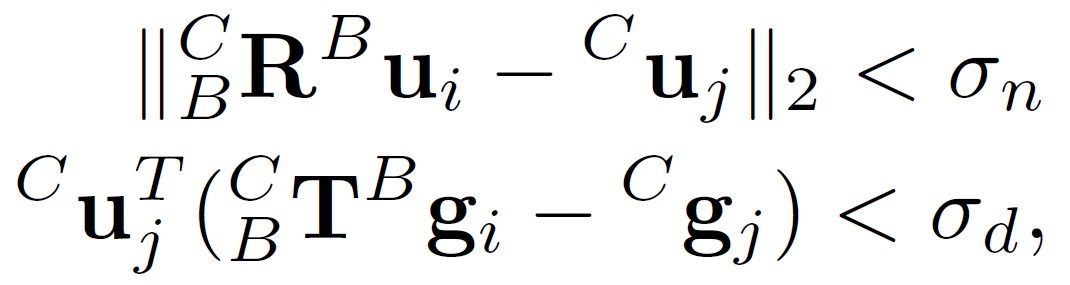
-
이후, candidate frame의 전체 plane voxel 개수 중에서 몇 개의 plane voxel이 일치하는지를 수치화하여 일정 수치를 넘기면 유효한 loop detection으로 처리한다.
-
위의 방식은 plane 수가 point clouds 수에 비해 훨씬 적기 때문에 ICP-based 방법들에 비해 훨씬 효율적이다. 또한, 위에서 구하는 normal vectors의 difference와 point-to-plane distance를 optimize하는 방법인 STD-ICP 또한 고안하였다. (ceres-solver 사용)
Experiments
-
Precision-Recall Evaluation
- Precision: True라고 예측한 것 중 실제 True인 값의 비율
- Recall: 실제 True인 값들 중 True라고 예측한 비율
- KITTI, NCLT, Complex Urban dataset에서 테스트하였고, M2DP, Scan Context에 비해 정확한 precision, recall 성능을 보였다.
- 두 알고리즘과는 달리, 좁은 환경에서도 높은 loop detection 확률을 보였다.
- 하지만 평면 정보가 부족한 scene에서는 나쁜 성능을 보였다.
-
Run Time Evaluation
- KITTI00 데이터셋에서만 descriptor 생성 시간, search loop 시간을 각각 계산하였다.
- Scan Context(가장 오래 걸림) » M2DP = STD 순으로 결과가 나왔다. 평균적으로 100ms 정도의 차이였다.
-
Localization Evaluation
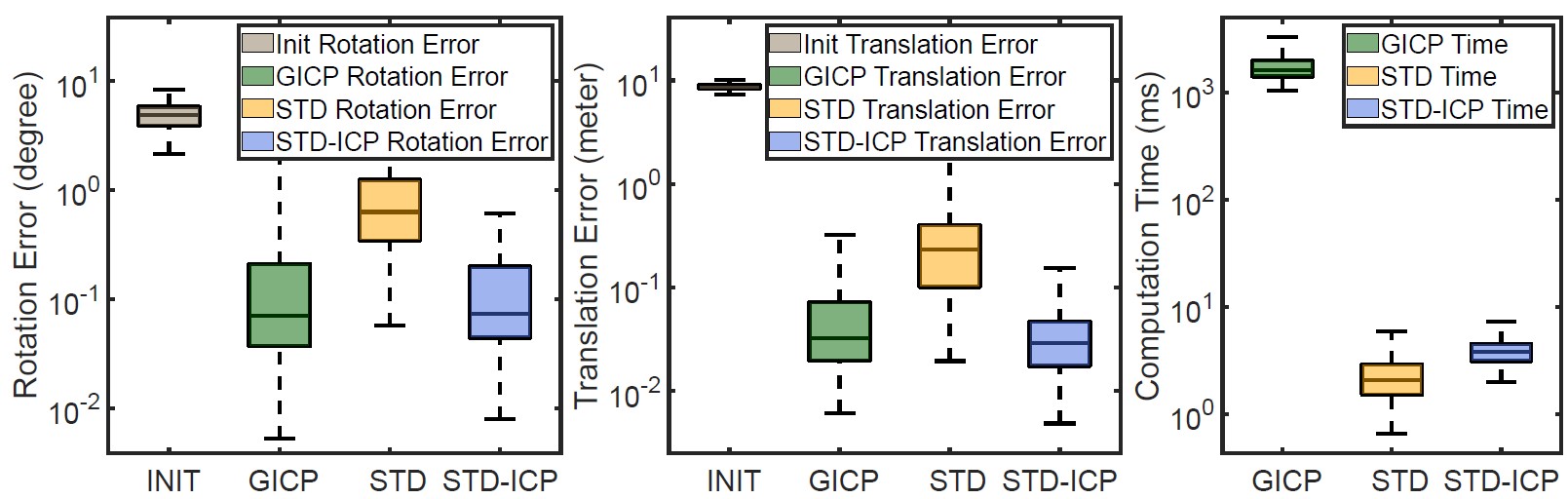
- G-ICP, STD, STD-ICP를 비교했다. STD와 STD-ICP의 차이는 STD를 통해 구한 transformation을 그대로 사용하는 것과, planes 사이의 normal vector 차이와 point-to-plane distance를 optimize를 추가로 한 차이이다.
- STD-ICP는 G-ICP와 비슷한 translation, rotation 정확도를 보였고, computation time은 STD, STD-ICP 모두 G-ICP의 1% 정도 밖에 걸리지 않았다.
-
추가적으로, Livox LiDAR를 통해 취득한 데이터, 실내 실외의 환경 등의 다양한 센서, 환경에서도 테스트를 하였다. M2DP와 비교를 하였고, 더 좋은 성능을 보였다.
Conclusion
-
Triangle-based descriptor STD는 plane detection을 기반으로 효율적인 key point extraction을 수행했고, boundary projection을 통해 key points와 geometrical feature를 추출했다.
-
이를 기반으로 생성한 descriptor는 rotation, translation에 invariant하고, 빠르고 안정적이고 distinguishable한 장점을 지닌다. 또한 Hash table로 descriptor를 관리하기 때문에 더욱 빠르다.
-
다른 기존 알고리즘에 비해 더욱 빠르고 정확하고, 다양한 환경이나 센서에도 robust한 결과를 보였다.
댓글남기기